Extraction and Imputation Module - Overview
Extraction and Imputation Module - Overview
The Extraction and Imputation Module of T-Rx package aims to transform raw prescription records into clean prescription records with ready-to-analyse data frames.
In a standard extraction & imputation pipeline, it consists of the following functions:
- Extraction of strength, quantity, multiplier
- Imputation of strength, quantity
- Further inference of quantity (under development, specific to datasets)
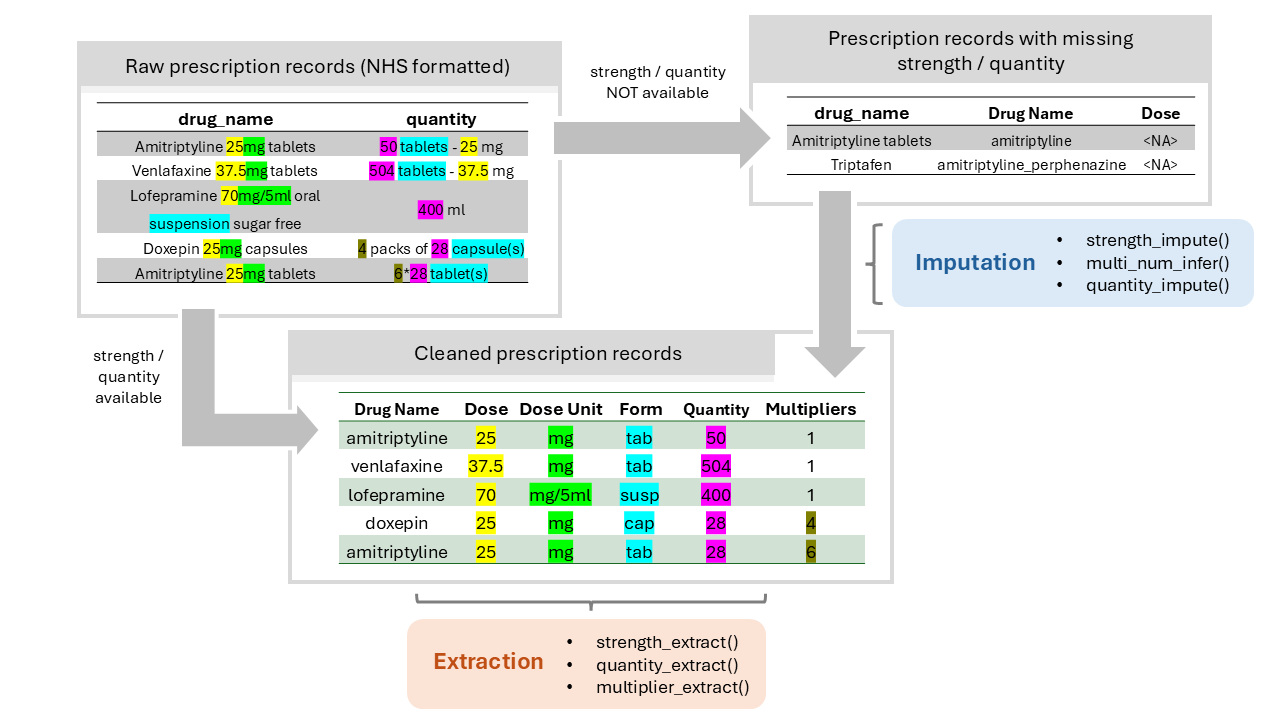
Figure 1: Overview of the Extraction & Imputation Module
Extraction
The algorithm utilizes regular expression (REGEX) patterns in prescription records, and extracts strength / dosage, as well as quantity information from prescription records.
In this module, users are required to specify:
- dosage units (e.g: “mg”, “mcg”, “mg/5ml”)
- dosage forms that captures units of quantity (e.g.: “tab”, “cap”, “suspension”)
Using these information, the numbers preceding user-specified dosage units / dosage forms are extracted as dose and quantity respectively.
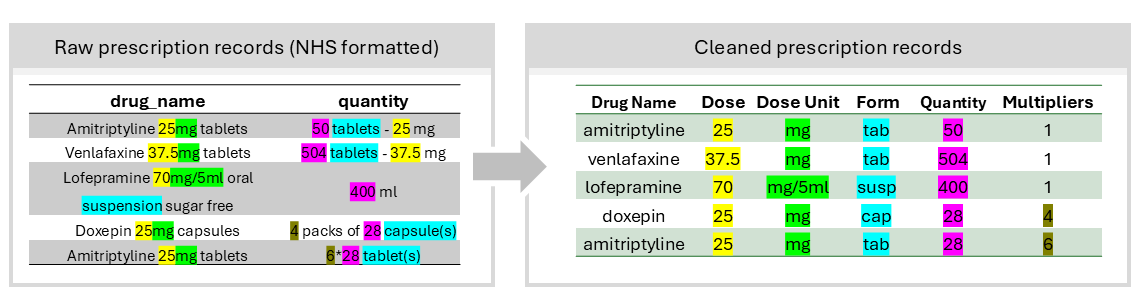
Figure 2: Regular expression pattern matching in the Extraction Module
Imputation
The presence of missingness is common in prescription records (such as dosage and quantity for example).
Besides, pharmaceutical products (especially combination products) were often coded as brand names instead of active ingredients, occasionally without the presence of dosage information.
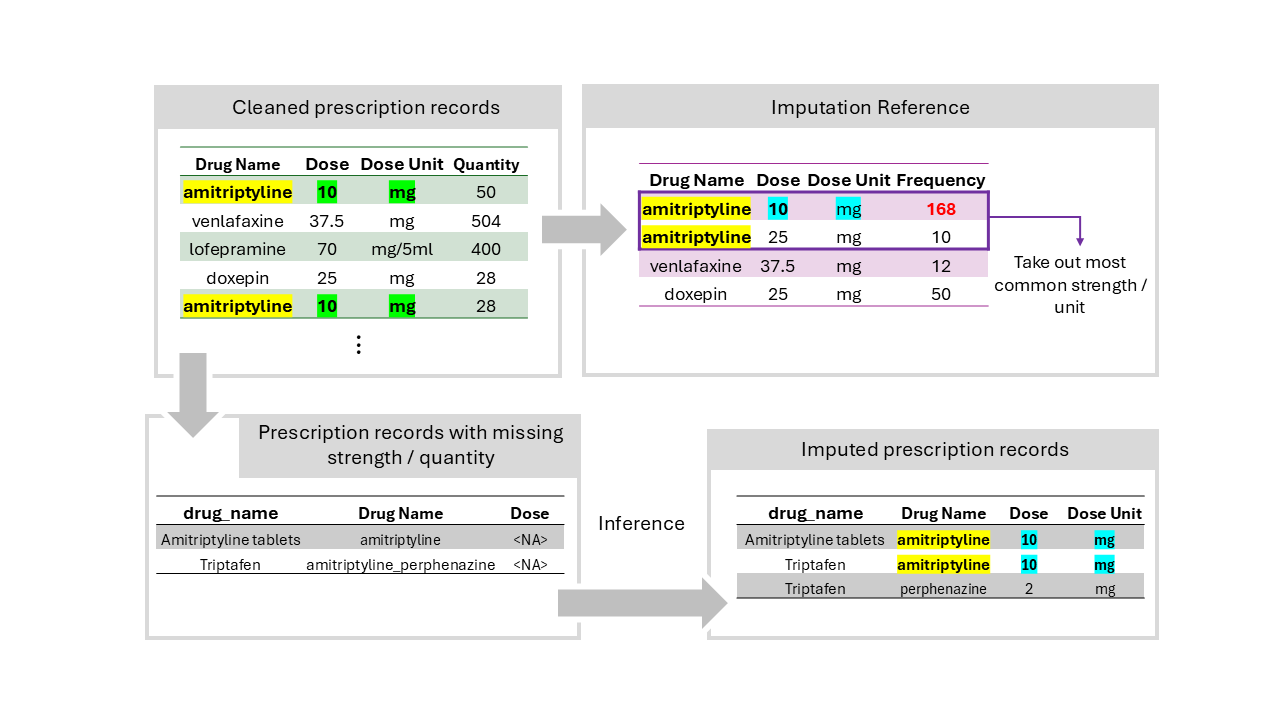
Figure 3: Overview in Imputation Module (using dose as example)
The imputation functions infer dosage / quantity information from cleaned prescription records (as outputs from extraction functions or run independently), with most commonly occurring dosage / quantity being assigned.
Any questions?
Please post questions as an issue on the T-Rx GitHub repo here.
The T-Rx package is currently under beta testing. Most functions should have adequate documentation on possible errors.
Please kindly reach out to Chris Lo (chris.lowh@kcl.ac.uk) for feedback on documentation.
![]()